

あぶちゃです。
このブログでは、AI業界への転職を考えている方に役立つ情報をお届けしています。転職に役立つヒントから最新のAIツールや技術の紹介をしています。本ブログによって、少しでもAIの魅力を感じていただけると嬉しいです!
 悩んでいる人
悩んでいる人Webスクレイピングができるって噂のSeleniumの使い方を知りたい!
以上のような要望にお答えしていきます。
- Webスクレイピングの概要
- Seleniumを使うことでなにができるか
- Seleniumを使ったWebスクレイピングの方法
あなたが探している情報を効率的に収集したいと思ったことはありませんか?
この記事では、Webスクレイピングを簡単に実現できるPythonとSeleniumの使い方を初心者向けにわかりやすく解説します。
PythonとSeleniumを使ってWebページから簡単に情報を取得する方法や、ブラウザの自動操作、フォームの入力などを学ぶことができます。
以下の記事では、AI職種を6つ紹介しています。未経験からでも転職は可能なので、AIに興味がある方は参考にしてみてください。

Webスクレイピングとは?
Webスクレイピングとは、インターネット上のWebページから必要な情報を抽出・収集する技術です。
Webスクレイピング技術を使うことで、日常生活に関連するさまざまな情報(天気予報、ニュース、レシピ、イベント情報など)を効率的に集めることができます。
わかりやすく言うと、Webサイトを操作して、Webサイトに記載されているたくさんの情報から必要な情報(テキスト、画像や動画など)のみを自動的に抽出して取得するための技術になります。
Webスクレイピングを使用することによって、手動でデータを収集する場合に比べて非常に高速かつ大量にデータを収集することができます。
webスクレイピングは、かなり強力なツールにも関わらず、最近の技術の進歩により、簡単に実現できるようになりました。
Pythonには、Webスクレイピングに特化したライブラリがいくつかあり、それらを使うことで簡単に情報を取得できます。
Webスクレイピングに特化したPythonライブラリの違い
Webスクレイピング用のPythonライブラリ
Pythonで使われる人気のWebスクレイピング用のライブラリは、主に以下の3つです。
- Selenium(セレニウム)
- Beautiful Soup(ビューティフル・スープ)
- Requests(リクエスト)
それぞれの違いについて解説していきます。
Selenium(セレニウム)
Webブラウザを操作することができるライブラリで、JavaScriptを扱うようなサイトに対してもスクレイピングが可能です。
ログインが必要なサイトや動的なコンテンツを取得する際に役立ちます。
ただ、他のライブラリに比べると、処理速度が遅いというデメリットがあります。
Beautiful Soup(ビューティフル・スープ)
「BeautifulSoup」は、HTMLやXMLの解析を行うライブラリで、Webページのソースコードを簡単に解析し、簡単にデータを抽出できます。
Webページのソースコードを簡単に解析し、特定のタグや属性を持つ要素を抽出できます。
ただし、Beautiful Soup自体はWebページの情報を取得する機能はありません。そのため、通常は次に紹介するRequestsと組み合わせて使用します。
Requests(リクエスト)
「requests」はPythonのHTTPライブラリで、WebサイトにアクセスしてHTMLデータを取得するのに使われます。
シンプルで直感的なAPIが特徴で、初心者にも扱いやすいです。
ただし、requests自体はスクレイピング機能を持っていないので、HTML解析を行う場合は先ほど紹介した「BeautifulSoup」などと組み合わせて使うことが一般的です。
例えば、気になるニュースサイトから最新記事のタイトルを取得する場合、まずはrequestsを使ってHTMLデータを取得し、次にBeautifulSoupで解析してタイトルを抽出するといった流れになります。
Seleniumを使ったWebスクレイピング
今回は、ログインが必要なサイトや動的なコンテンツを取得することができるSeleniumに関しての解説をしていきます。
Seleniumの主な機能
Seleniumの主な機能として、以下の3つの機能があります。
- ウェブページの操作: ブラウザを開いてウェブページを表示したり、リンクをクリックしたり、テキストを入力したりすることができます。
- ページ内の要素の取得: ウェブページの特定の要素(例えば、テキストや画像)を取得して、それを利用することができます。
- 動的なウェブページの操作: JavaScriptやAjaxなどを使った動的なウェブページも、操作することができます。
PythonとSeleniumを使ったWebスクレイピングの例
PythonとSeleniumを使うことでどのようなことが実現できるかを知ってもらうために、以下に、PythonとSeleniumを使ったWebスクレイピングの例をいくつか紹介します。
商品価格情報の収集
例えば、あるECサイトの商品価格情報を収集する場合、Seleniumを使って商品ページに自動的にアクセスし、商品名や価格情報をスクレイピングすることができます。
これにより、商品価格の変動情報を自動的に取得することができます。
天気情報の収集
天気情報サイトから天気情報をスクレイピングする場合、Seleniumを使って地域選択や日付指定などの入力を自動化し、Webページから必要な情報を収集することができます。
これにより、天気予報情報を自動的に取得することができます。
ニュース記事の収集
ニュースサイトから最新のニュース記事を収集する場合、Seleniumを使ってニュースサイトにアクセスし、記事のタイトルや本文をスクレイピングすることができます。
これにより、最新のニュース情報を自動的に収集することができます。
Seleniumを使う際の注意点
Seleniumを使う前に知っておくべき注意点を以下にまとめましたので、以下のことに気をつけてSeleniumを活用してください。
- Webサイトの利用規約を確認する:Webスクレイピングや自動操作を行う前に、対象のWebサイトの利用規約を確認し、規約に違反しないように注意してください。
- アクセス頻度を制限する:Webサイトへのアクセス頻度が高すぎると、サーバーに負荷をかけることになり、IPアドレスがブロックされることがあります。アクセス間隔に適切な時間を設けることが重要です。
- セキュリティ対策:自動操作やスクレイピングを行う際に、セキュリティ上のリスクがあることを意識してください。例えば、ログイン情報などの機密情報を安全に管理し、スクレイピング対象のWebサイトに対して適切なアクセス権限を持っていることを確認してください。
他のWebサイトに迷惑をかけないよう、適切にSeleniumを使いこなせるようになりましょう!
Seleniumを使うための事前準備と使用環境
Seleniumは、Google Chrome、Firefox、Safari、Microsoft Edge、Internet Explorerなど、多くのブラウザに対応しています。
今回は、多くの方が使用しているGoogle Chromeを使った方法をご紹介します。
Seleniumのインストール
以下のコマンドをターミナルで実行して、Seleniumをインストールしてください。
pip install seleniumgoogle chromeドライバーの入手
Google Chromeドライバーは、SeleniumでChromeを制御するために必要になります。
Seleniumを使ってWebスクレイピングを行うために、以下の手順に従って、Chromeドライバーを入手してください。
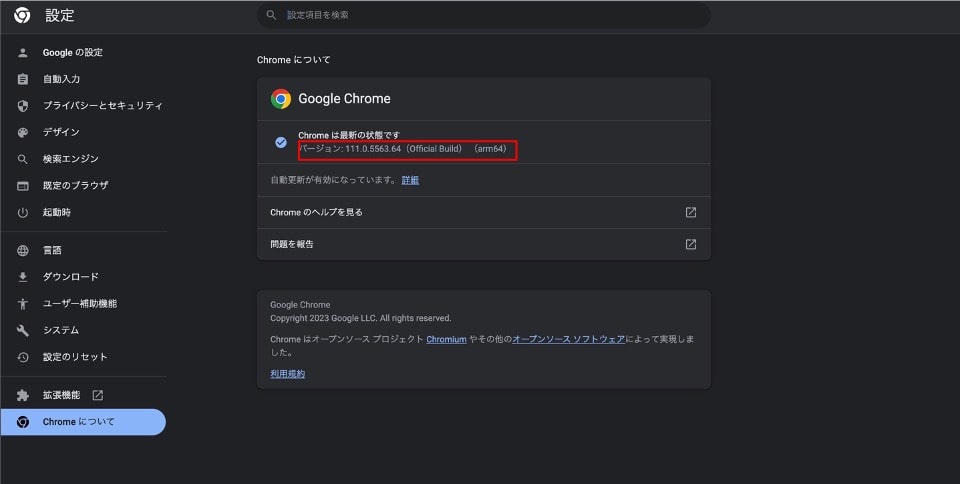
Chromeのバージョンを確認する
現在、使用しているGoogle Chromeブラウザのバージョンを確認してください。
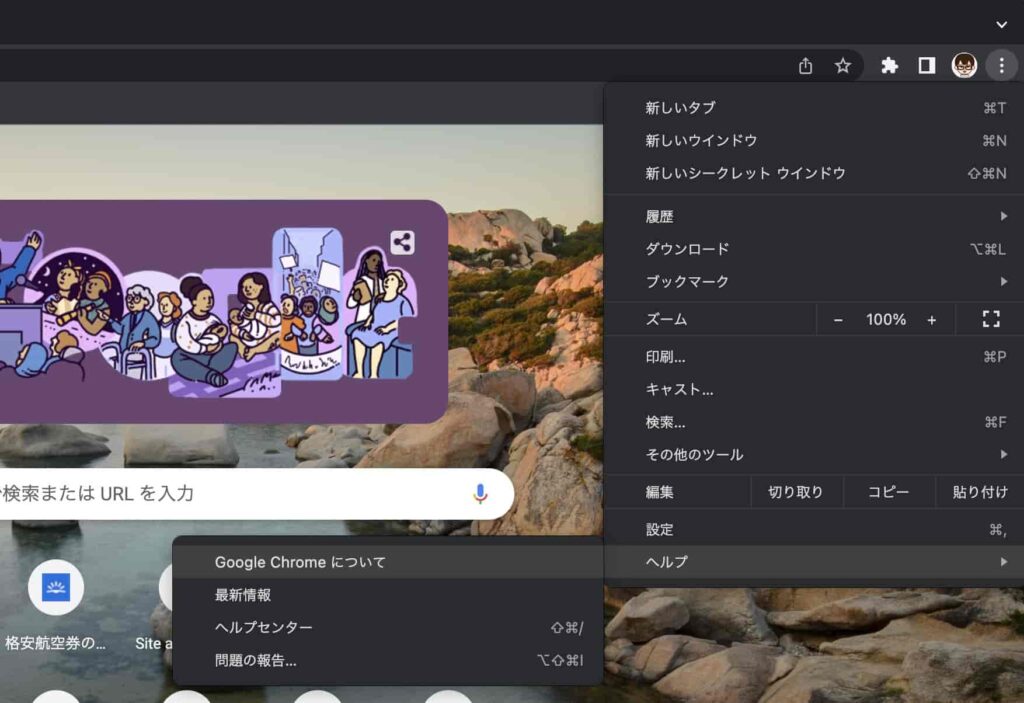
Chromeブラウザを開いて、右上にある縦三点リーダーをクリックし、「ヘルプ」→「Google Chromeについて」をクリックすることで確認できます。
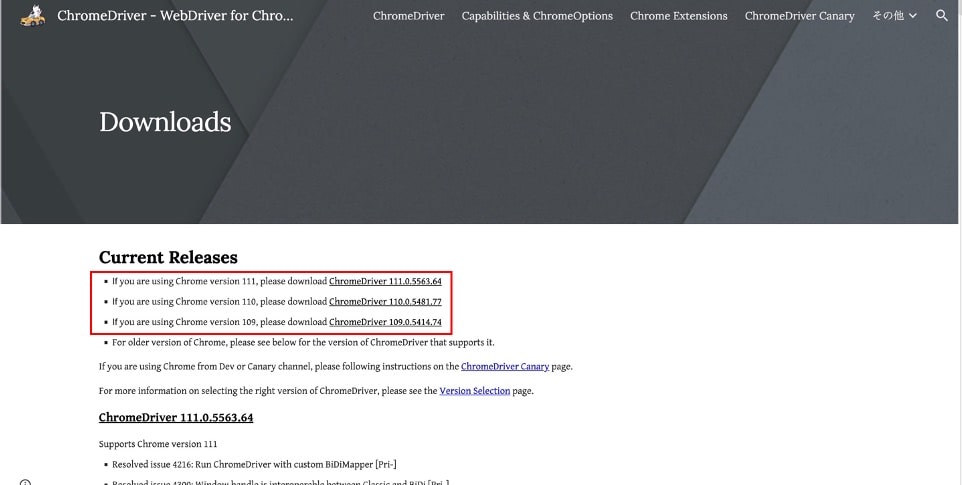
Chromeドライバーのダウンロードリンクにアクセス
Chromeドライバーのサイトから自身のバージョンに対応するChromeドライバーのダウンロードリンクをクリックしてください。
最初の3桁が一致しているものを選んでください。
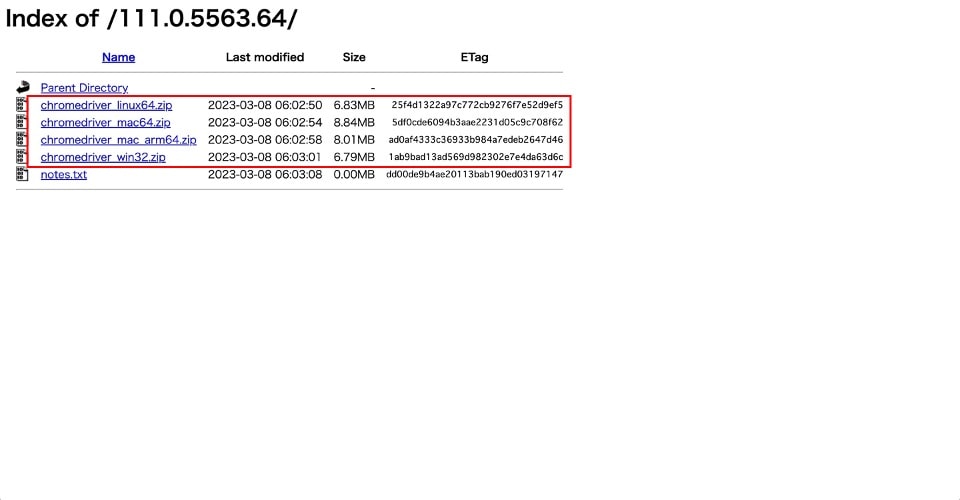
Chromeドライバーのダウンロード
自身のパソコンのOSに対応するzipファイルをダウンロードしてください。
Chromeドライバーをプログラムフォルダに配置する。
ダウンロードしたChromeドライバーを任意の場所に保存してください。
本記事の場合は、pythonファイルを保存した場所に保存しました。
コード内で、保存先のパスを定義できるようにしたので、自分がわかりやすい場所に保存していただいても大丈夫です。
Chromeドライバーへのアクセス権限の付与 (Macを使用している場合)
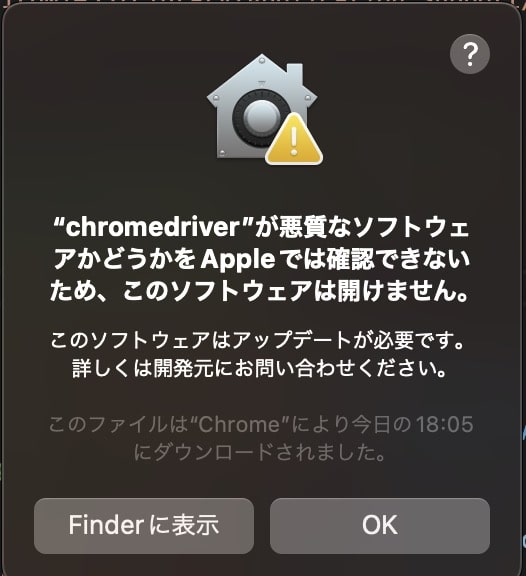
その場合は、「システム設定」→「プライバーとセキュリティ」の”セキュリティ”の項目の中に、以下の画像のようにChromeドライバーへのアクセスを許可する箇所がありますので、許可をすることでChromeドライバーが使用できるようになります。
googleアカウントのプロフィールパス取得
Seleniumを使ってgoogleにアクセスする際、googleアカウントを指定してあげないと以下の問題が発生します。
そこで、Cookieの設定が完了しているgoogleアカウントのプロフィールパスを取得して指定してあげましょう。
google アカウントのプロフィールパスの取得方法は以下になります。
- Google Chromeを開き、アドレスバーに「chrome://version」と入力
- 「プロフィール パス」という項目が表示されるので、その横にあるフォルダパスをコピーして取得(下図、参照)
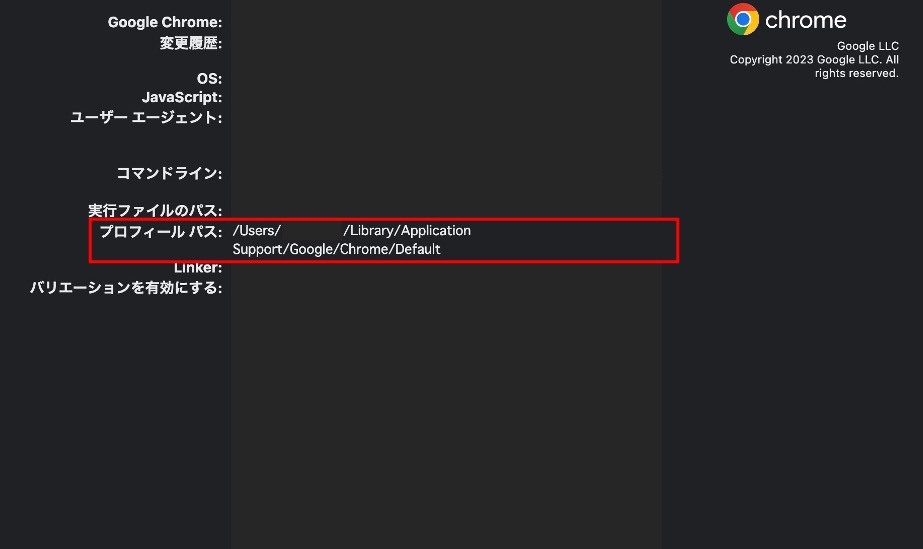
取得したプロフィールのパスをコード内で指定しましょう。
もし、Cookieの表示が出てしまう場合は、一度、Cookieを許可してあげることで次から表示がでないようになります。
使用環境
今回、使用した作業環境は以下になります。
今回の作業環境
- Mac Apple M1
- MacOS Ventura 13.2.1
- python 3.9.7
- Selenium 4.8.2
Seleniumの基本的な使い方
Webページ上の要素を取得する方法
Seleniumでは、以下のような標準のロケータ(ページ上の要素を識別する方法)を使って、Webページ上の要素を取得することができます。WebDriverには標準のロケータが8種類あります。
Seleniumの公式サイトで、ロケーターに関して説明されているページはこちら。
| ロケーター | 概要 | メソッド |
| id | id属性が一致する要素を探す | driver.find_element_by_id(‘element_id’) |
| name | name属性が一致する要素を探す | driver.find_element_by_name(‘element_name’) |
| class name | class名に値を含む要素を探す (複合クラス名は使えない) |
driver.find_element_by_class_name(‘element_class’) |
| tag name | タグ名が一致する要素を探す | driver.find_element_by_tag_name(‘element_tag’) |
| css selector | CSSセレクタが一致する要素を探す | driver.find_element_by_css_selector(‘css_selector’) |
| xpath | XPathと一致する要素を探す | driver.find_element_by_xpath(‘xpath_expression’) |
| link text | a要素のテキストが一致する要素を探す | driver.find_element_by_link_text(‘link_text’) |
| partial link text | a要素のテキストが部分一致する要素を探す | driver.find_element_by_partial_link_text(‘partial_link_text’) |
取得した要素に対して実行できる操作
Seleniumで取得した要素に対して、以下のような一般的な操作を実行できます。
要素に対して実行できる基本的なコマンドは5つになります。
Seleniumの公式サイトで、実行できる操作に関して説明されているページはこちら。
| コマンド | 概要 | メソッド |
| クリック | 要素をクリック | element.click() |
| テキスト入力 | テキストボックスに文字列を入力 | element.send_keys(‘input_text’) |
| テキスト取得 | 要素のテキストを取得 | element.text |
| 属性取得 | 要素の属性値を取得 | element.get_attribute(‘attribute_name’) |
| 要素の有無 | 要素が存在するかどうかを確認 | element.is_displayed() |
ブラウザでの要素確認方法
必要な情報の取得を自動化するために、Google Chromeの開発者ツールを使って、Webページ上の要素を確認し、Seleniumで要素を取得するための適切なロケータ(ページ上の要素を識別する方法)を見つける必要があります。
ブラウザでの要素確認方法は、以下になります。
Google Chromeを開く
まずは、Google Chromeを使用してWebページを開いてください。
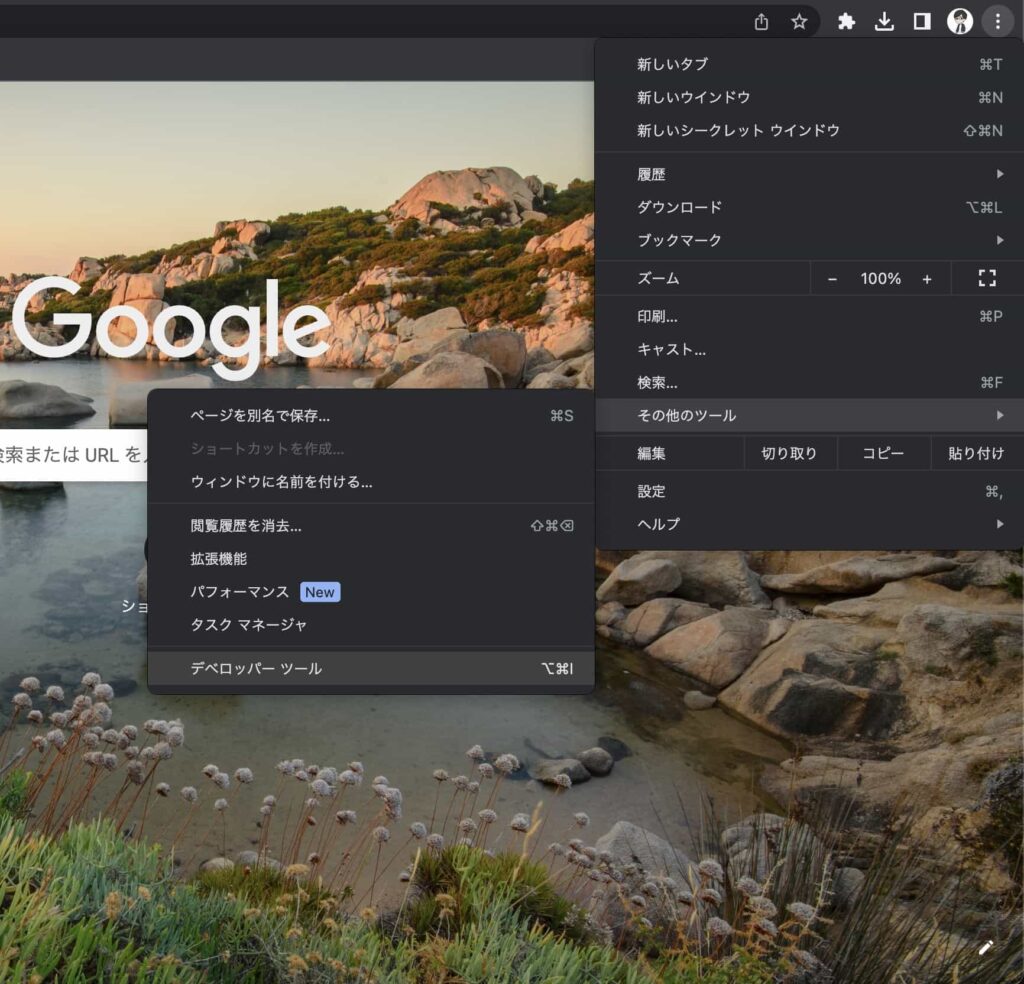
開発者ツールを開く
次に、Google Chromeが提供している機能である開発者ツールを以下の方法で開く必要があります。
- Chromeの右上にある縦三点リーダーをクリック
- その他のツールを選択
- デベロッパーツールをクリック
確認したい要素の選択
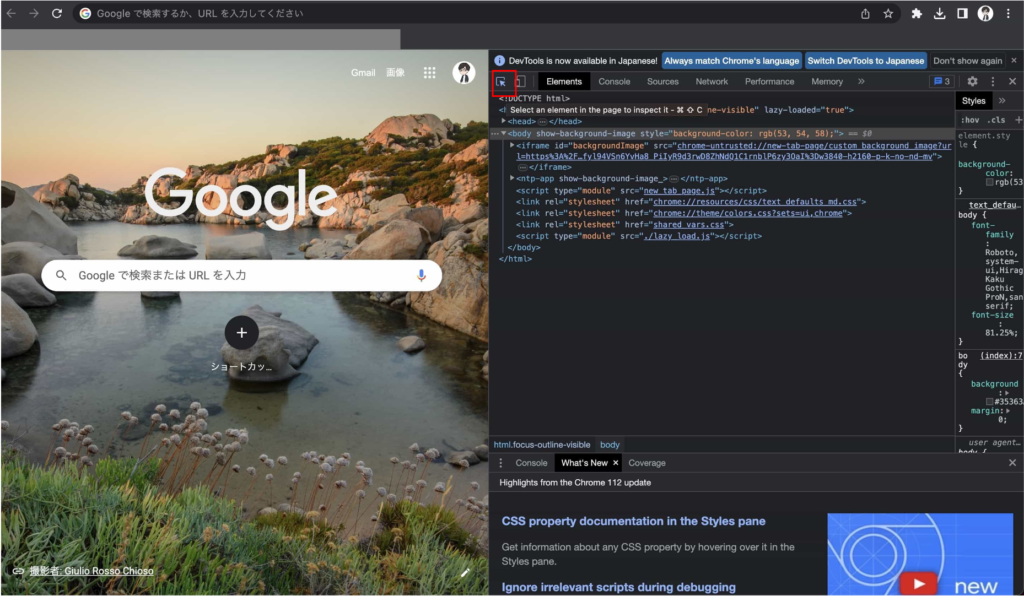
要素を選択できるモードを使用して、確認したい要素を選択します。
開発者ツールの左上のアイコン(矩形にマウスカーソル)をクリックすることで、要素を選択できるモードに移行できます。
そして、ページ上の要素をクリックすることで、要素を確認することができます。
選択した要素の確認
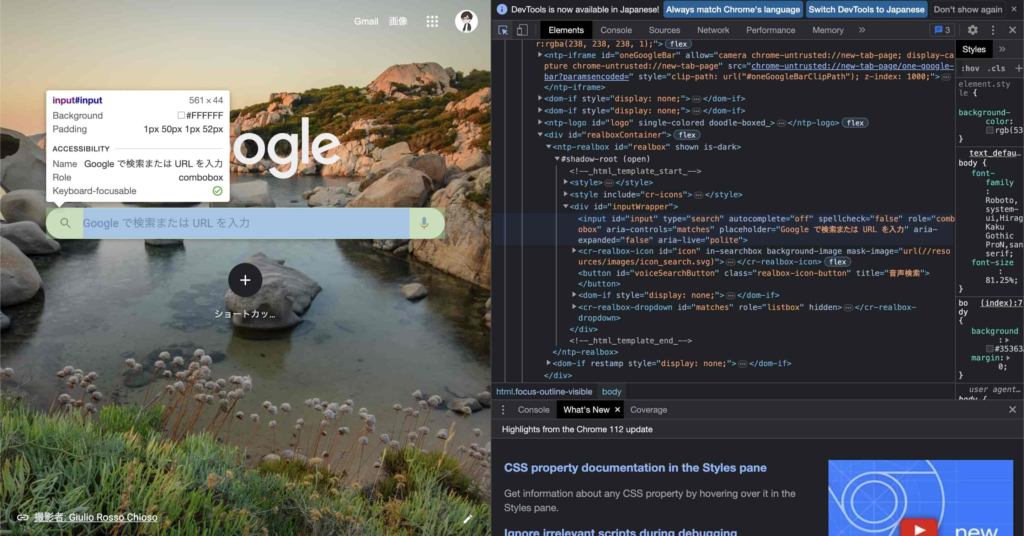
選択した要素の詳細が開発者ツールの「Elements」タブに表示されます。
ここで、ID、name、class、CSSセレクタ、XPathなどを確認することができます。
下図の画像のようにgoogleの検索窓を要素として選択した場合、検索窓の要素の詳細が開発者ツールの「Elements」タブに薄青色がついた形で表示されます。
SeleniumのPythonコード例
Seleniumを使った活用例として、以下の3つの活用方法でのPythonコードを示します。
- Webブラウザの自動化
- Webページのスクレイピング
- フォームの自動操作
以下のコードを参考にしながら色々と試してみましょう!
Webブラウザの自動化
まずは、Webブラウザの自動化するための基本的なPythonコードの例になります。
Google検索で「AI Life Hacks あぶちゃ」と検索し、最初の検索結果をクリックするPythonコードです。
23行目の「AI Life Hacks あぶちゃ」を別の言葉に変えることで、他の言葉で検索をすることができます。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
# chrome driverのパスを入力
chrome_driver_path = 'chrome driverを保存したフォルダのパスをいれてください'
# google アカウントのプロフィールパス定義
profile_path = "使用したいgoogle アカウントのプロフィールのパスを入力してください"
# google chrome プロフィールパス定義
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--user-data-dir="+profile_path)
# Chromeブラウザを開く
driver = webdriver.Chrome(executable_path=chrome_driver_path, options=chrome_options)
# Googleのトップページにアクセス
driver.get('https://www.google.com/')
# 検索ボックスを見つけて、キーワード「AI Life Hacks あぶちゃ」を入力
search_box = driver.find_element_by_name('q')
search_box.send_keys('AI Life Hacks あぶちゃ')
search_box.send_keys(Keys.RETURN)
# 検索結果が表示されるまで少し待つ
time.sleep(2)
# 最初の検索結果をクリック
first_result = driver.find_element_by_css_selector('.g a')
first_result.click()
Seliniumのコード解説【Webブラウザの自動化】
- Seleniumのモジュールのインポート
-
from selenium import webdriver from selenium.webdriver.common.keys import KeysSeleniumライブラリから
webdriverモジュールとKeysモジュールをインポートするためのコードですWebDriverは、Webブラウザを操作するためのインターフェースを、Keysはブラウザ上でのキー入力を行うためのインターフェースを提供してくれます。 - ChromeブラウザのWebDriverインスタンスの作成
-
# Chromeブラウザを開く driver = webdriver.Chrome(executable_path=chrome_driver_path, options=chrome_options)driver = webdriver.Chrome()でChromeブラウザのWebDriverインスタンスを作成しています。これにより、Chromeブラウザを自動操作できるようになります。FirefoxやEdgeなど他のブラウザを使いたい場合は、
webdriver.Firefox()やwebdriver.Edge()のように記述します。 - 指定したURLにアクセス
-
# Googleのトップページにアクセス driver.get('https://www.google.com/')driver.get('アクセスしたいURLを指定')で、指定したURLにアクセスできます。 - ページ内の特定の要素を取得
-
search_box = driver.find_element_by_name('q')driver.find_element_by_...は、ページ内の特定の要素を取得ために使われるロケーターです。driver.find_element_by_name('q')は、name属性がqの要素を取得します。 - 検索ボックスにテキストを入力
-
search_box.send_keys('AI Life Hacks あぶちゃ') search_box.send_keys(Keys.RETURN)element.send_keys('text')は、テキストボックスなどの入力要素にテキストを入力するために使われます。ここで'text'の部分には、入力したい文字列を指定します。 - 要素のクリック
-
# 最初の検索結果をクリック first_result = driver.find_element_by_css_selector('.g a') first_result.click()element.click()は、要素(例えばボタンやリンク)をクリックするために使われます。これにより、ページ遷移やフォームの送信などを行うことができます。
Webページのスクレイピング
次は、Webページのスクレイピングするための基本的なPythonコードの例になります。
WikipediaのPythonページにアクセスし、「概要」部分の最初の文章を取得するPythonコードです。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
# chrome driverのパスを入力
chrome_driver_path = 'chrome driverを保存したフォルダのパスをいれてください'
# google アカウントのプロフィールパス定義
profile_path = "使用したいgoogle アカウントのプロフィールのパスを入力してください"
# google chrome プロフィールパス定義
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--user-data-dir="+profile_path)
# Chromeブラウザを開く
driver = webdriver.Chrome(executable_path=chrome_driver_path, options=chrome_options)
# WikipediaのPythonページにアクセス
driver.get('https://ja.wikipedia.org/wiki/Python')
# 概要部分の要素を取得
summary = driver.find_elements_by_css_selector('#mw-content-text .mw-parser-output p')
# 概要テキストを出力
print(summary[2].text)
driver.close()- ページ内の特定の要素を取得
-
# 概要部分の要素を取得 summary = driver.find_elements_by_css_selector('#mw-content-text .mw-parser-output p')この例では、CSSセレクタによって、要素を取得しています。
WekipediaのPythonページの「概要」部分の最初の文章が、”mw-content-text” “.mw-parser-output”内の複数あるうちの一つのpタグ要素になります。(#はID属性で、.はクラス属性です)
複数のタグを取得するためには、
find_elements_by_css_selector()のようにelementの部分を複数形のelementsにする必要があります。 - 概要の最初の文章を出力
-
# 概要テキストを出力 print(summary[2].text)複数取得した要素のうちの3つ目のpタグが取得したい要素のため、
summary[2]により3つ目のpタグを取得しています。
フォームの自動操作
最後は、フォームの自動操作のための基本的なPythonコードの例になります。
ログイン画面にアクセスし、自動でログインに必要な情報を入力し、ログインするPythonコードになります。
ログインページは適当なURLになっていますので、実際にログインしたいURLに変えて試してみてください。
ログインページに応じて、「ユーザー名」、「パスワード」、「ログインボタン」の要素を取得できるようにコードを修正する必要があります。
少し意地悪ですが、ここは自分でやってみてください!
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# chrome driverのパスを入力
chrome_driver_path = 'chrome driverを保存したフォルダのパスをいれてください'
# google アカウントのプロフィールパス定義
profile_path = "使用したいgoogle アカウントのプロフィールのパスを入力してください"
# google chrome プロフィールパス定義
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--user-data-dir="+profile_path)
# Chromeブラウザを開く
driver = webdriver.Chrome(executable_path=chrome_driver_path, options=chrome_options)
# ログインページにアクセス
driver.get('https://example.com/login')
# ユーザー名入力欄を見つけて、ユーザー名を入力
username_box = driver.find_element_by_name('username')
username_box.send_keys('your_username')
# パスワード入力欄を見つけて、パスワードを入力
password_box = driver.find_element_by_name('password')
password_box.send_keys('your_password')
# ログインボタンを見つけて、クリック
login_button = driver.find_element_by_css_selector('.login-button')
login_button.click()
“最後に” PythonとSeleniumでできること | まとめ
本記事では、PythonとSeleniumを用いて、Webスクレイピングを実現する方法を解説しました。
本記事で紹介している内容とPythonコードにより、PythonとSeleniumを使ったWebスクレイピングの基本的な使い方を身につけることができましたか?
今回学んだ知識を活かして、あなたの日常生活や仕事に役立つ情報収集や自動化を実現してみてください!
以下の記事では、Seleniumを用いたWebスクレイピングにより、ブログの競合サイトを調べる自作ツールを作っていますので参考にしてみてください。ブログに興味がない方もより複雑なWebスクレイピングの方法を学ぶことができます。

最後まで、お付き合いいただきまして、ありがとうございました。



